Als Beispiel-Projekt habe ich eine Geo-App entwickelt. welche den Standort von Schlösser und Burgen in Oberösterreich visualisiert. Sie dient zur Ergründung solcher Bauwerke in der eigenen Umgebung, kann auch Informationen beim Wandern bereit stellen oder zur Planung von Ausflügen verwendet werden.
Dieser Eintrag wird den Entstehungsprozess thematisieren. Die App selbst ist auf folgender Seite erreichbar:
Daten von Wikipedia
 |
| Burg Ruttenstein, Foto © S. Wiesinger, 2014 |
Auf das touristisch verwertbare Thema,
Schlösser und Burgen, bin ich durch einen
offenen Datensatz des Landes OÖ gekommen. Wie sich jedoch erst heraus stellte, fehlten in diesem Datensatz eine größere Anzahl an Objekten, insbesonders (aber nicht nur) die touristisch interessanten Burgruinen. Aus den Metadaten war das so leider auch nicht ersichtlich. Genau so unzuverlässig und halbherzig dokumentiert sollten Open Data eigentlich nicht sein.
Als Alternative habe ich mich für die Verwendung von Daten von Wikipedia entschieden. Dazu habe ich ein kleines Script geschrieben, das die jeweilgen Namen der Bauwerke, einen Link zur jeweiligen Wikipedia Seite (als Information für die Pop-Ups in der App) und die Geokoordinaten extrahiert. Die Verortung ist zwar weniger genau, als jene im Datensatz des Landes, jedoch ist die Anzahl der Objekte umfassender, insbesonders die erwähnten Ruinen kommen hierbei auch vor. Darüber hinaus klassifiziert das Script die Bauwerke noch, um eine Unterscheidung zwischen Burgen und Schlösser bei der Visualisierung zu ermöglichen. Bei den von den 324
aufgelisteten Objekten, konnten nur 5 wegen mangelnder Geoverortung oder nicht Verfolgbarkeit der Links nicht verwendet werden. Im Vergleich dazu umfasst der Datensatz des Landes nur 240 Objekte.
Um Oberösterreich hervor zu heben, habe ich wieder auf einen
DORIS Datensatz vom Land OÖ zurück gegriffen. Dieser ist zwar stark generalisiert, was aber im Kontext dieser App ein Vorteil ist, da Speicherplatz und Ladezeiten dadurch vermindert werden. Um Zweiteres zu verbessern wird er vor dem Rendern im Browser auch noch weiter generalisiert.
Die extrahierten Daten wurden dann in QGIS geoprozessiert und in ein Datenmodell transformiert. Dieses wurde mit MongoDB umgesetzt, da dessen Schemalosigkeit die Entwicklung vereinfachte und die damit mögliche Geoindexierung effiziente Abfragen versprach.
 |
| Übersicht Karte |
Flask-App mit Bootstrap Frontend
Das Backend der App basiert auf dem Python Framework Flask und wie erwähnt MongoDB. Die Architektur folgt einem vereinfachten MVC Modell.
 |
| Marker mit Pop-Up |
Das Frontend wurde auf dem Bootstrap Framework aufgesetzt, vor allem um die App auch responsiv zu gestalten. Das ist besonders für den Anwendungsfall der mobilen Abfrage von Objekten nötig, beispielsweise wenn sich ein/e Benutzer/in beim Wandern oder einem Spaziergang befindet und erfahren möchte, wo sich die nächste Burg oder das nächste Schloss befindet. Grundsätzlich nimmt den größten Teil der Frontpage die ganzseitige Karte mit den visualisierten Objekten ein. Eine Navigationsleiste ermöglicht noch das Aufrufen einer kurzen Anleitung und Informationen über die Daten und der App. Diese Informationen wurden auf eine eigene Seite ausgelagert.
Die Kommunikation zwischen Front- und Backend wurde mit einem Zusammenspiel von Flask mit AJAX und jQuery umgesetzt und könnte bei weitem besser entwickelt sein - bin leider kein Software Ingenieur. In diesem Zusammenhang sei auch erwähnt, dass die App für einen unternehmerischen Einsatz an manchen Stellen noch robuster programmiert werden müsste. Für ein Beispiel, das die Möglichkeiten mit den verwendetetn Daten und Techniken zeigt, sollte dieser Entwicklungsstand aber ausreichen.
Geo-App mit Leaflet
Die Karte selbst wurde mit Leaflet umgesetzt. Mein Konzept für die Visualisierung konnte damit (und auch Dank der verwendeten Plugins) sehr effizient umgesetzt werden.
Als Basiskarte habe ich mich für das Open Static Map Service von MapQuest entschieden. Der Toner Style von Stamen Design hätte zwar grafik-design-technisch mehr her gegeben, aber die MapQuest Tiles geben durch ihr Farbschema visuell Informationen über die geografische Verortung der Bauwerke intuitiver preis.
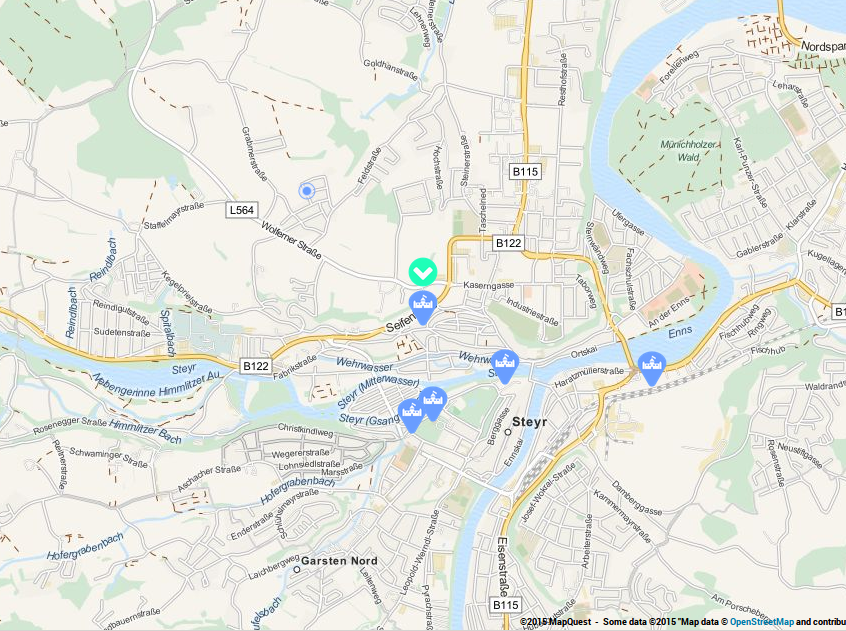 |
| Standortbestimmung |
Der Standort der Schlösser und Burgen wird durch Marker angezeigt. Ein Piktogramm darauf zeigt an, zu welchem Typ das Objekt gehört. Durch das Auswählen eines Markers mittels Click, öffnet sich ein Pop-Up, das den Namen des Bauwerks und einen Link zu dessen Seite auf Wikipedia enthält, um sich näher über das jeweilge Schloss oder die Burg informieren zu können.
Mit einem Button auf der Karte, ist es möglich, seinen eigenen Standort durch die App anzeigen zu lassen. Dabei wird auf Geoinformation aus dem Browser zurück gegriffen, was erst mit mobilen Geräten wirklich Sinn macht. Dennoch ist die Standortbestimmung damit nicht in allen Gegenden, auch trotz dem Einsatz von GPS, wirklich gut. Über die Einschränkungen ist
dieser Artikel recht informativ. Jedenfalls, als Näherungswert, sollte die Bestimmung dennoch ausreichen.
Sobald die App den Standpunkt bestimmt hat, wird aus der Datenbank das geografisch nächste Schloss oder die nächste Burg abgefragt. Die Bestimmung des nächsten Objekts vereinfacht der räumliche Index in MongoDB ungemein und ist mit einer einfachen Anfrage auszuführen. Auf der Karte wird das nächste Bauwerk dann mit einem eigenen Marker hervorgehoben.
Deployment auf OpenShift
Weil die Datenbank wenig umfangreich ist und sich auch der Rechenaufwand zur Darstellung der Page in Grenzen hält, wird die App auf einem einzigen Gear in OpenShift gehostet. Problematisch war hierbei nur die alte Version von MongoDB in der Standard-Cartridge. Da die App mit einer neueren Version der Geoindizes lokal entwickelt wurde, habe ich eine aktuelle Version in OpenShift nachgerüstet - was Dank der
MongoDB 2.6 Cartridge von Ionut-Cristian Florescu kein großes Problem war.
Zusammenfassung
Mit der Entwicklung dieser Geo-App habe ich versucht zu zeigen, wie es möglich ist mit relativ simplen Mitteln und offenen Daten die Visualisierung von Standorten von mehreren Objekten umzusetzen. Das Thema des Beispielprojekts,
Schlösser und Burgen in Oberösterreich, ist touristisch nutzbar. Das beschriebene Vorgehen ist aber auch auf andere statische Objekte wie beispielsweise Geschäftsniederlassungen, Standorte von sportlichen oder kulturellen Einrichtungen etc. anwendbar. Erweiterungsmöglichkeiten sind auch vorhanden, beispielsweise im Rendern von 3D-Modellen der einzelnen Bauwerke an ihren Standorten bei hohen Zoomstufen.
Aus Sicht der Sozialforschung ist der Blick auf die Karte auch nicht uninteressant, liefert sie doch eine Darstellung der Verteilung von machtdarstellenden Bauwerken in früheren Zeiten. Dabei ist besonders markant (wenn auch nicht unlogisch), dass sich solche Gebäude in jenen Gebieten konzentrieren, die noch Heute bevölkerungsreich sind, wohin gegen in ländlichen Regionen solche Objekte verstreut in der Landschaft liegen, wobei diese nicht zwangsläufig in Nähe aktueller regionaler Zentren liegen müssen. Hinsichtlich der Sozialforschung ist des weiteren auch bemerkenswert, dass gemeinschaftlich auf Wikipedia erstellte Information, nicht nur umfangreicher, sondern auch gültiger sein kann, als ein von offizieller Stelle publizierter Datensatz.
Die zum Projekt gehörenden Scripte und der Source Code der App sind im
Webbeispiele Repository dieses Blogs ersichtlich. Für die Planung von Tageausflüge und -in eingeschränktem Masse- auch mobil für die Orientierung bei einer Wanderung, lässt sich die App auf jedem Fall nutzen. Auch das Ergründen von bislang einem noch unbekannten Bauwerke kann ganz spannend sein.
 |
| Burgruine Ruttenstein, Foto © S. Wiesinger, 2014 |



